
¿Alguna vez escuchó el término robots.txt y se preguntó cómo se aplica a su sitio web? La mayoría de los sitios web tienen un archivo robots.txt, pero eso no significa que la mayoría de los webmasters lo entiendan. En esta publicación, esperamos cambiar eso ofreciendo una inmersión profunda en el archivo robots.txt de WordPress, así como también cómo puede controlar y limitar el acceso a su sitio. Al final, podrá responder preguntas como:
¿Qué es un WordPress Robots.txt?
Antes de que podamos hablar sobre el archivo robots.txt de WordPress, es importante definir qué es un «robot» en este caso. Los robots son cualquier tipo de «bot» que visita sitios web en Internet. El ejemplo más común son los rastreadores de motores de búsqueda. Estos bots se “rastrean” por la web para ayudar a los motores de búsqueda como Google a indexar y clasificar los miles de millones de páginas de Internet.
Entonces, los bots son, en general , algo bueno para Internet … o al menos algo necesario. Pero eso no significa necesariamente que usted, u otros webmasters, quieran que los bots corran sin restricciones. El deseo de controlar cómo los robots web interactúan con los sitios web llevó a la creación del estándar de exclusión de robots a mediados de la década de 1990. Robots.txt es la implementación práctica de ese estándar: le permite controlar cómo los bots participantes interactúan con su sitio . Puede bloquear bots por completo, restringir su acceso a ciertas áreas de su sitio y más.
Sin embargo, esa parte de «participar» es importante. Robots.txt no puede obligar a un bot a seguir sus directivas. Y los robots maliciosos pueden ignorar el archivo robots.txt y lo harán. Además, incluso las organizaciones de renombre ignoran algunos comandos que puede poner en Robots.txt. Por ejemplo, Google ignorará las reglas que agregue a su archivo robots.txt sobre la frecuencia con la que visitan sus rastreadores. Si tiene muchos problemas con los bots, una solución de seguridad como Cloudflare o Sucuri puede ser útil.
¿Por qué debería preocuparse por su archivo Robots.txt?
Para la mayoría de los webmasters, los beneficios de un archivo robots.txt bien estructurado se reducen a dos categorías:
- Optimización de los recursos de rastreo de los motores de búsqueda diciéndoles que no pierdan tiempo en páginas que no desea que se indexen. Esto ayuda a garantizar que los motores de búsqueda se centren en rastrear las páginas que más le interesan.
- Optimización del uso de su servidor mediante el bloqueo de bots que están desperdiciando recursos.
Robots.txt no se trata específicamente de controlar qué páginas se indexan en los motores de búsqueda
Robots.txt no es una forma infalible de controlar qué páginas indexan los motores de búsqueda. Si su objetivo principal es evitar que determinadas páginas se incluyan en los resultados de los motores de búsqueda, el enfoque adecuado es utilizar una metaetiqueta noindex u otro método directo similar.
Esto se debe a que su Robots.txt no les está diciendo directamente a los motores de búsqueda que no indexen el contenido, solo les está diciendo que no lo rastreen. Si bien Google no rastreará las áreas marcadas desde el interior de su sitio, Google mismo afirma que si un sitio externo se vincula a una página que usted excluye con su archivo Robots.txt, Google aún podría indexar esa página.
John Mueller, un analista de webmasters de Google, también ha confirmado que si una página tiene enlaces que apuntan a ella, incluso si está bloqueada por robots.txt, aún podría indexarse . A continuación, se muestra lo que tuvo que decir en un Hangout del Centro para webmasters:
Una cosa a tener en cuenta aquí es que si estas páginas están bloqueadas por robots.txt, entonces, en teoría, podría suceder que alguien se vincule aleatoriamente a una de estas páginas. Y si lo hacen , podría suceder que indexemos esta URL sin ningún contenido porque está bloqueada por robots.txt. Por lo tanto, no sabríamos que no desea tener estas páginas indexadas.
Mientras que si no están bloqueados por robots.txt, puede poner una metaetiqueta noindex en esas páginas. Y si alguien se enlaza con ellos, y nosotros rastreamos ese enlace y pensamos que tal vez haya algo útil aquí, entonces sabríamos que estas páginas no necesitan ser indexadas y podemos simplemente omitirlas por completo.
Entonces, en ese sentido, si tiene algo en estas páginas que no desea que se indexe, no lo rechace, use noindex en su lugar.
Cómo crear y editar su archivo WordPress Robots.txt
De forma predeterminada, WordPress crea automáticamente un archivo robots.txt virtual para su sitio. Entonces, incluso si no mueve un dedo, su sitio ya debería tener el archivo robots.txt predeterminado. Puede probar si este es el caso agregando “/robots.txt” al final de su nombre de dominio. Por ejemplo, «https://joypixel-wordpress-wordpress.xyjthp.easypanel.host/robots.txt» muestra el archivo robots.txt que usamos aquí en Joypixel:

Sin embargo, debido a que este archivo es virtual, no puede editarlo. Si desea editar su archivo robots.txt, deberá crear un archivo físico en su servidor que pueda manipular según sea necesario. Aquí hay tres formas sencillas de hacerlo …
Cómo crear y editar un archivo Robots.txt con Yoast SEO
Si está utilizando el popular complemento Yoast SEO, puede crear (y luego editar) su archivo robots.txt directamente desde la interfaz de Yoast. Sin embargo, antes de poder acceder a él, debe habilitar las funciones avanzadas de Yoast SEO yendo a SEO → Panel de control → Funciones y activando las páginas de configuración avanzada:
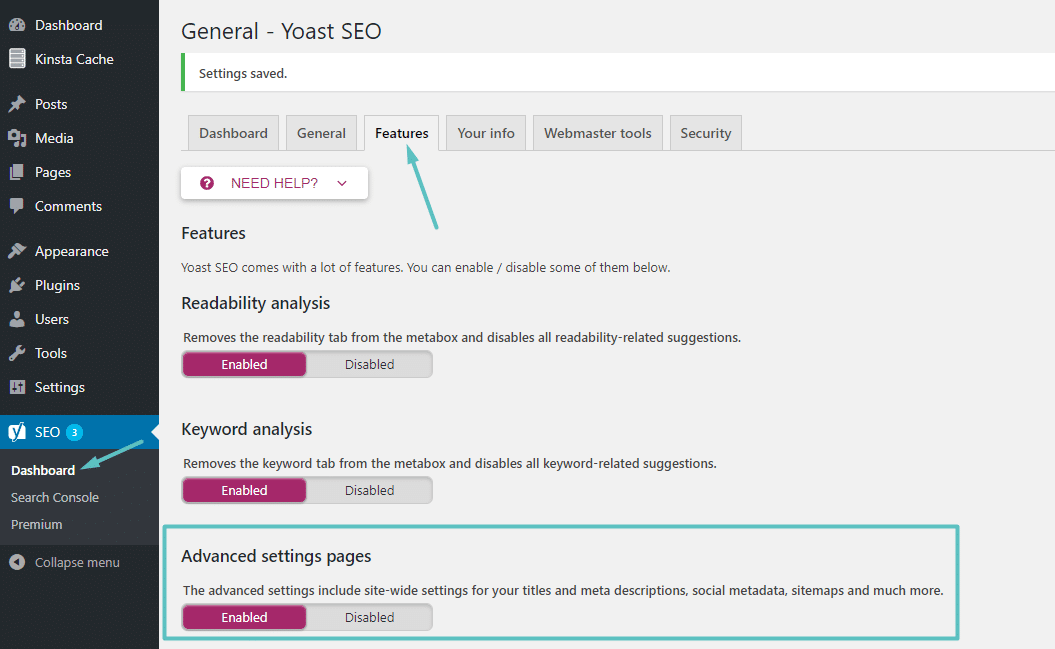
Una vez que esté activado, puede ir a SEO → Herramientas y hacer clic en Editor de archivos :
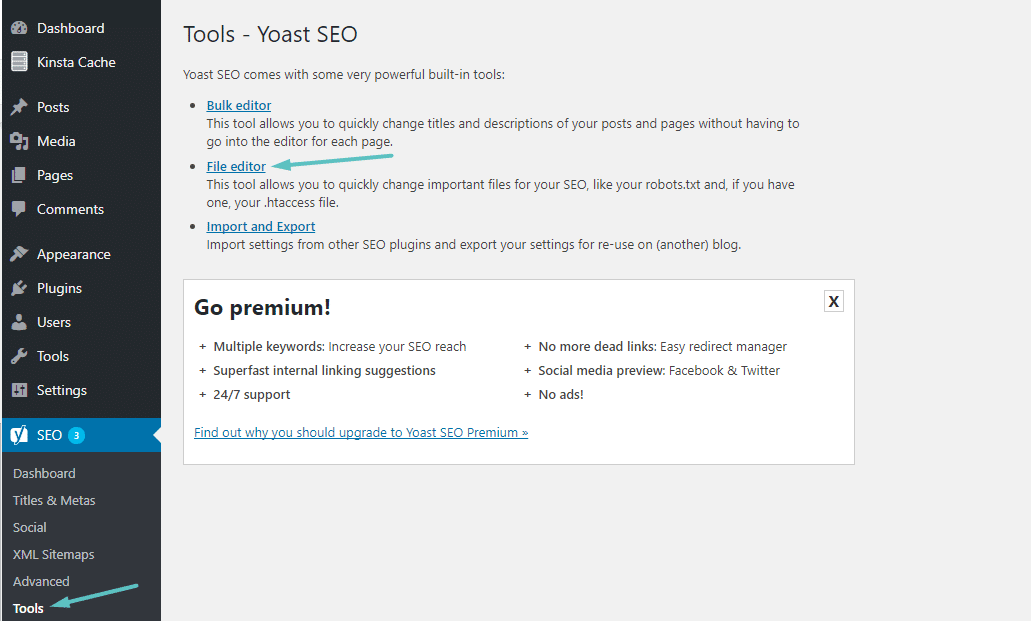
Suponiendo que aún no tiene un archivo Robots.txt físico, Yoast le dará una opción para crear un archivo robots.txt :
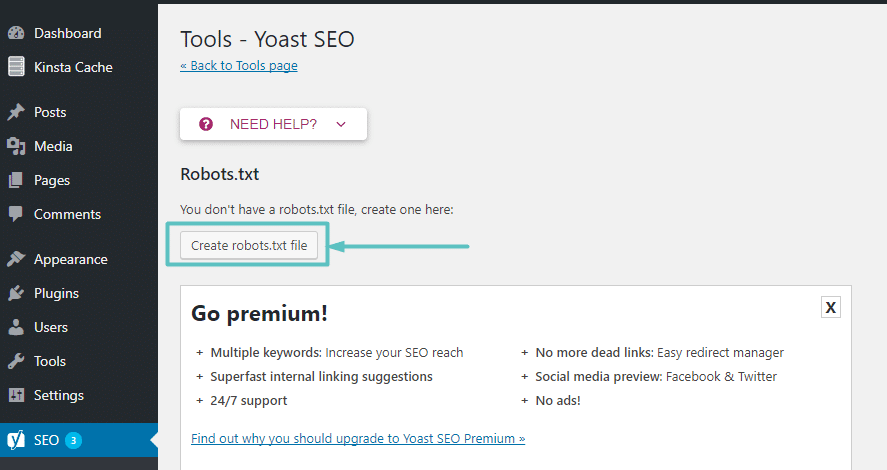
Y una vez que haga clic en ese botón, podrá editar el contenido de su archivo Robots.txt directamente desde la misma interfaz:
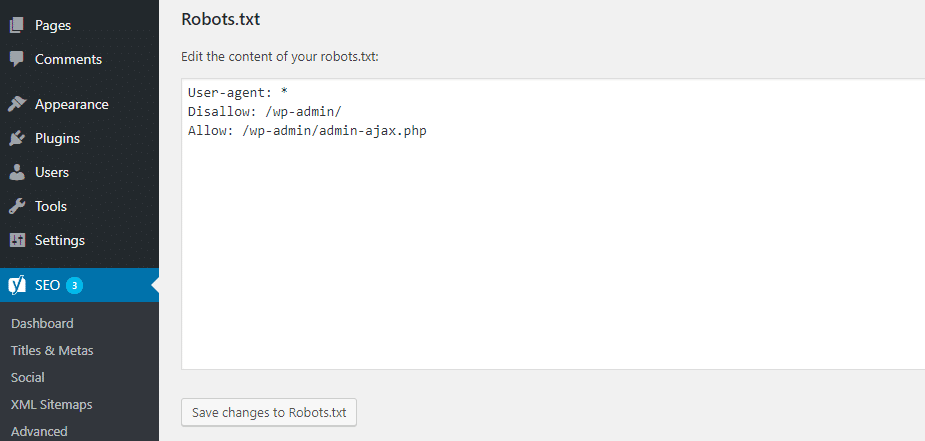
A medida que lea, profundizaremos más en qué tipos de directivas poner en su archivo robots.txt de WordPress.
Cómo crear y editar un archivo Robots.txt con todo en uno SEO
Si está utilizando el complemento All in One SEO Pack casi tan popular como Yoast , también puede crear y editar su archivo robots.txt de WordPress directamente desde la interfaz del complemento. Todo lo que necesita hacer es ir a All in One SEO → Feature Manager y Activar la función Robots.txt :
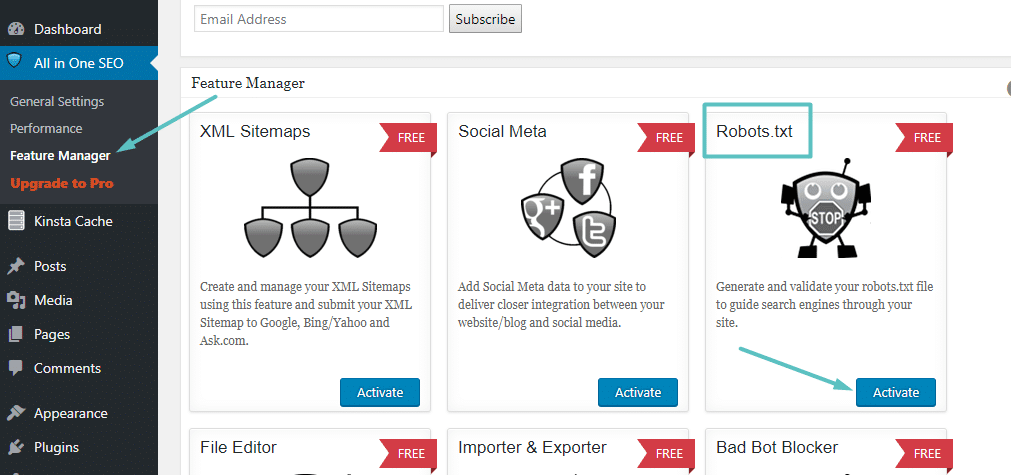
Luego, podrá administrar su archivo Robots.txt yendo a All in One SEO → Robots.txt:
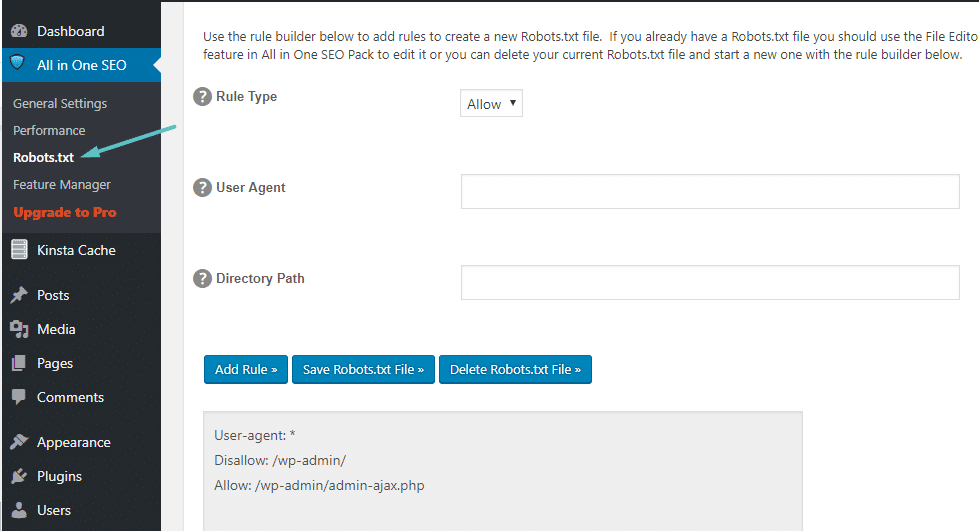
Cómo crear y editar un archivo Robots.txt a través de FTP
Si no está utilizando un complemento de SEO que ofrezca la funcionalidad de robots.txt, aún puede crear y administrar su archivo robots.txt a través de SFTP. Primero, use cualquier editor de texto para crear un archivo vacío llamado «robots.txt»:
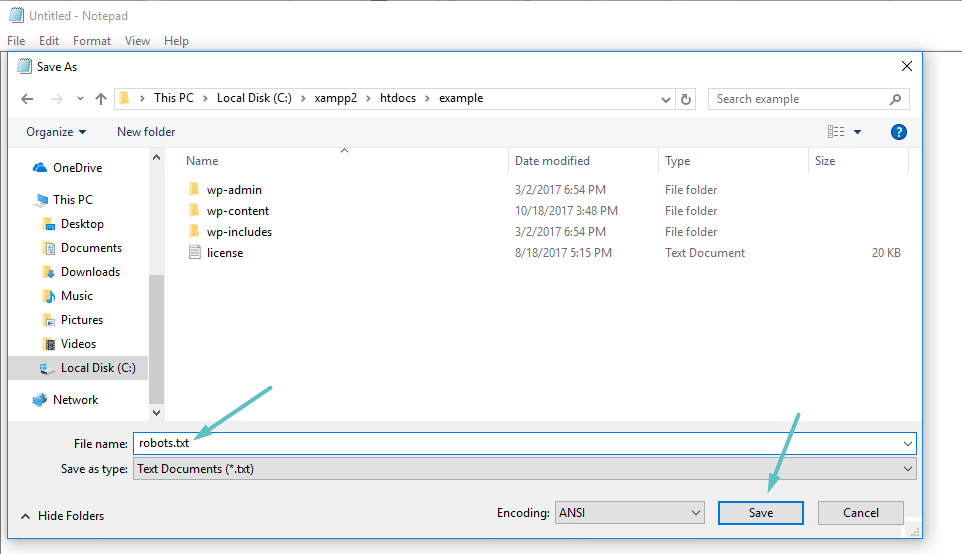
Luego, conéctese a su sitio a través de SFTP y cargue ese archivo en la carpeta raíz de su sitio. Puede realizar más modificaciones en su archivo robots.txt editándolo a través de SFTP o cargando nuevas versiones del archivo.
Qué poner en su archivo Robots.txt
Bien, ahora tiene un archivo robots.txt físico en su servidor que puede editar según sea necesario. Pero, ¿qué haces realmente con ese archivo? Bueno, como aprendió en la primera sección, robots.txt le permite controlar cómo los robots interactúan con su sitio. Lo haces con dos comandos básicos:
- Usuario-agente : esto le permite apuntar a bots específicos. Los agentes de usuario son lo que utilizan los bots para identificarse. Con ellos, podría, por ejemplo, crear una regla que se aplique a Bing, pero no a Google.
- No permitir : esto le permite decirle a los robots que no accedan a ciertas áreas de su sitio.
También hay un comando Permitir que usará en situaciones específicas. De forma predeterminada, todo en su sitio está marcado con Permitir , por lo que no es necesario usar el comando Permitir en el 99% de las situaciones. Pero es útil cuando desea No permitir el acceso a una carpeta y sus carpetas secundarias, pero Permitir el acceso a una carpeta secundaria específica.
Usted agrega reglas especificando primero a qué User-agent se debe aplicar la regla y luego enumerando qué reglas aplicar usando Disallow y Allow . También hay algunos otros comandos como Crawl-delay y Sitemap , pero estos son:
- Ignorado por la mayoría de los rastreadores principales, o interpretado de formas muy diferentes (en el caso del retraso del rastreo)
- Hecho redundante por herramientas como Google Search Console (para mapas de sitio)
Repasemos algunos casos de uso específicos para mostrarle cómo se combina todo esto.
Cómo usar Robots.txt para bloquear el acceso a todo su sitio
Supongamos que desea bloquear todo el acceso del rastreador a su sitio. Es poco probable que esto ocurra en un sitio en vivo, pero es útil para un sitio de desarrollo. Para hacer eso, debe agregar este código a su archivo robots.txt de WordPress:
User-agent: *
Disallow: /¿Qué está pasando en ese código?
El asterisco * junto a User-agent significa «todos los agentes de usuario». El asterisco es un comodín, lo que significa que se aplica a todos los agentes de usuario. La barra inclinada al lado de Disallow dice que quiere prohibir el acceso a todas las páginas que contienen «yourdomain.com/» (que son todas las páginas de su sitio).
Cómo usar Robots.txt para bloquear el acceso de un solo bot a su sitio
Cambiemos las cosas. En este ejemplo, fingiremos que no le gusta el hecho de que Bing rastree sus páginas. Eres el Equipo de Google en todo momento y ni siquiera quieres que Bing mire tu sitio. Para evitar que solo Bing rastree su sitio, debe reemplazar el asterisco comodín * con Bingbot:
User-agent: Bingbot
Disallow: /Esencialmente, el código anterior dice que solo se aplique la regla Disallow a los bots con el agente de usuario «Bingbot» . Ahora, es poco probable que desee bloquear el acceso a Bing, pero este escenario es útil si hay un bot específico al que no desea acceder a su sitio. Este sitio tiene una buena lista de los nombres de User-agent conocidos de la mayoría de los servicios.
Cómo usar Robots.txt para bloquear el acceso a una carpeta o archivo específico
Para este ejemplo, digamos que solo desea bloquear el acceso a un archivo o carpeta específicos (y todas las subcarpetas de esa carpeta). Para que esto se aplique a WordPress, digamos que desea bloquear:
- Toda la carpeta wp-admin
- wp-login.php
Puede utilizar los siguientes comandos:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-login.phpCómo usar Robots.txt para permitir el acceso a un archivo específico en una carpeta no permitida
Bien, ahora digamos que desea bloquear una carpeta completa, pero aún desea permitir el acceso a un archivo específico dentro de esa carpeta. Aquí es donde el comando Permitir resulta útil. Y en realidad es muy aplicable a WordPress. De hecho, el archivo robots.txt virtual de WordPress ilustra perfectamente este ejemplo:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phpEste fragmento bloquea el acceso a toda la carpeta /wp-admin/ excepto al archivo /wp-admin/admin-ajax.php .
Cómo usar Robots.txt para evitar que los bots rastreen los resultados de búsqueda de WordPress
Un ajuste específico de WordPress que quizás desee hacer es evitar que los rastreadores de búsqueda rastreen sus páginas de resultados de búsqueda. De forma predeterminada, WordPress utiliza el parámetro de consulta «? S =». Entonces, para bloquear el acceso, todo lo que necesita hacer es agregar la siguiente regla:
User-agent: *
Disallow: /?s=
Disallow: /search/Esta puede ser una forma eficaz de detener también los errores 404 leves si los está recibiendo.
Cómo crear diferentes reglas para diferentes bots en Robots.txt
Hasta ahora, todos los ejemplos se han ocupado de una regla a la vez. Pero, ¿qué pasa si desea aplicar diferentes reglas a diferentes bots? Simplemente necesita agregar cada conjunto de reglas en la declaración de agente de usuario para cada bot. Por ejemplo, si desea crear una regla que se aplique a todos los bots y otra regla que se aplique solo a Bingbot , puede hacerlo así:
User-agent: *
Disallow: /wp-admin/
User-agent: Bingbot
Disallow: /En este ejemplo, se bloqueará el acceso de todos los bots a /wp-admin/, pero se bloqueará el acceso de Bingbot a todo su sitio.
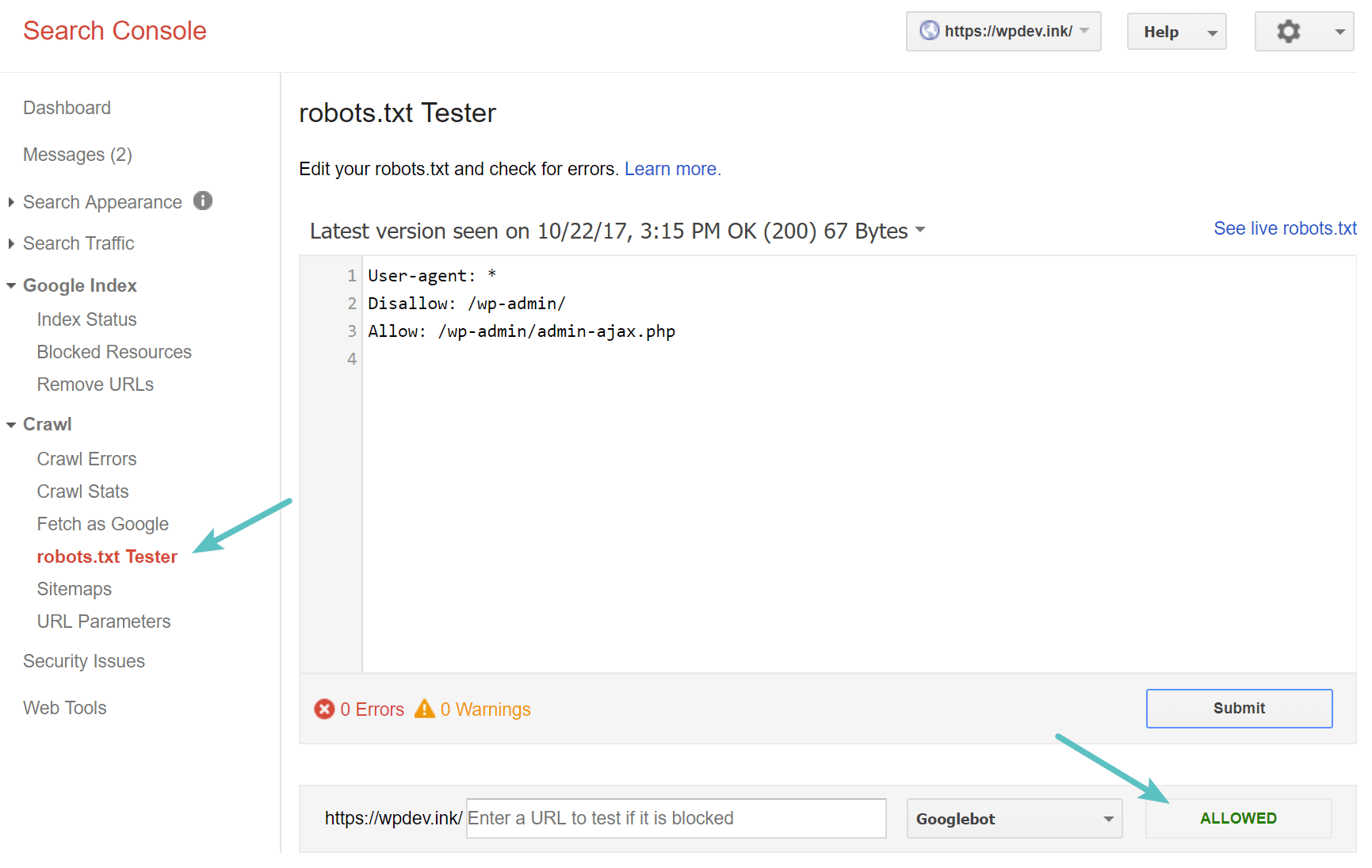
Prueba de su archivo Robots.txt
Puede probar su archivo robots.txt de WordPress en Google Search Console para asegurarse de que esté configurado correctamente. Simplemente haga clic en su sitio y, en «Rastrear», haga clic en «Probador de robots.txt». A continuación, puede enviar cualquier URL, incluida su página de inicio. Debe consultar a un verde mascotas si todo es rastreable. También puede probar las URL que ha bloqueado para asegurarse de que de hecho estén bloqueadas o no permitidas .
Tenga cuidado con la lista de materiales UTF-8
BOM significa marca de orden de bytes y es básicamente un carácter invisible que a veces los editores de texto antiguos y similares agregan a los archivos. Si esto le sucede a su archivo robots.txt, es posible que Google no lo lea correctamente. Por eso es importante comprobar si hay errores en su archivo. Por ejemplo, como se ve a continuación, nuestro archivo tenía un carácter invisible y Google se queja de que no se entiende la sintaxis. Esto esencialmente invalida la primera línea de nuestro archivo robots.txt por completo, ¡lo cual no es bueno! Glenn Gabe tiene un excelente artículo sobre cómo un UTF-8 Bom podría acabar con tu SEO .

Googlebot se basa principalmente en EE. UU.
También es importante no bloquear el robot de Google de los Estados Unidos, incluso si su objetivo es una región local fuera de los Estados Unidos. A veces realizan un rastreo local, pero el robot de Google se basa principalmente en EE.UU .
Qué sitios populares de WordPress ponen en su archivo Robots.txt
Para proporcionar algo de contexto para los puntos enumerados anteriormente, aquí se explica cómo algunos de los sitios de WordPress más populares utilizan sus archivos robots.txt.
TechCrunch
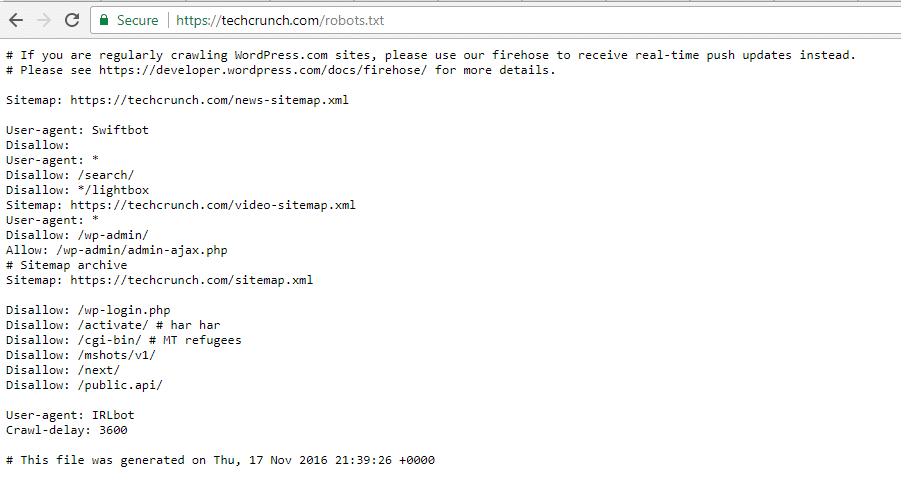
Además de restringir el acceso a varias páginas únicas, TechCrunch prohíbe notablemente a los rastreadores:
- /wp-admin/
- /wp-login.php
También establecen restricciones especiales en dos bots:
- Swiftbot
- IRLbot
En caso de que esté interesado, IRLbot es un rastreador de un proyecto de investigación de la Universidad de Texas A&M . ¡Eso es extraño!
Fundación Obama
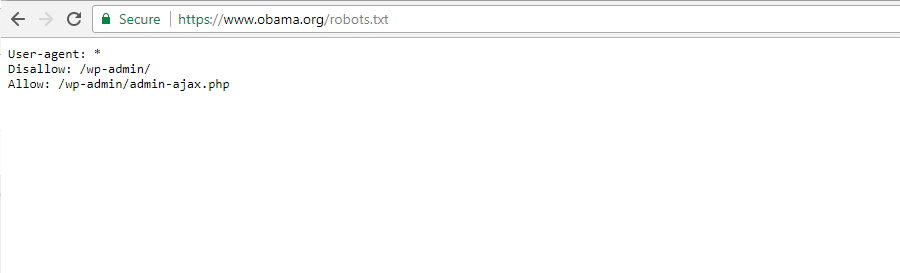
La Fundación Obama no ha hecho ninguna adición especial, optando exclusivamente por restringir el acceso a / wp-admin /.
Angry Birds
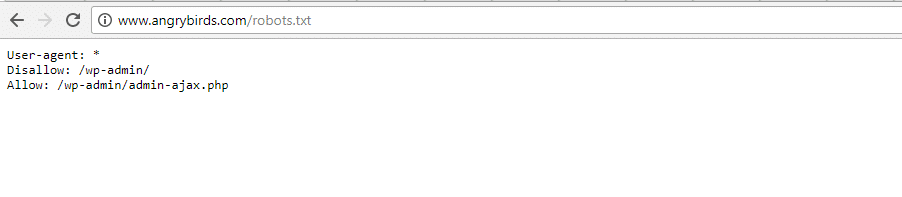
Angry Birds tiene la misma configuración predeterminada que la Fundación Obama. No se agrega nada especial.
Drift

Finalmente, Drift opta por definir sus mapas de sitio en el archivo Robots.txt, pero por lo demás, deja las mismas restricciones predeterminadas que The Obama Foundation y Angry Birds.
Use Robots.txt de la manera correcta
Al concluir nuestra guía de robots.txt, queremos recordarle una vez más que usar un comando No permitir en su archivo robots.txt no es lo mismo que usar una etiqueta noindex . Robots.txt bloquea el rastreo, pero no necesariamente la indexación. Puede usarlo para agregar reglas específicas para dar forma a cómo los motores de búsqueda y otros bots interactúan con su sitio, pero no controlará explícitamente si su contenido está indexado o no.
Para la mayoría de los usuarios ocasionales de WordPress, no existe una necesidad urgente de modificar el archivo robots.txt virtual predeterminado. Pero si tiene problemas con un bot específico o desea cambiar la forma en que los motores de búsqueda interactúan con un determinado complemento o tema que está utilizando, es posible que desee agregar sus propias reglas.
Esperamos que haya disfrutado de esta guía y asegúrese de dejar un comentario si tiene más preguntas sobre el uso de su archivo robots.txt de WordPress.
———
Fuente original: Kinsta